We'll see how gprof and KCachegrind lie to us and why they do so, discuss the limits within which we can trust them nonetheless, and attempt to draw more general conclusions about profilers and profile visualization tools.
(In case your programming vocabulary is different from mine – I use "lying" in its dispassionate meaning of "communicating falsehoods" and not to convey negative judgement; on the contrary, I'm indebted to the authors of profiling tools both as a user and a developer of such tools.)
So, consider a program with two parts – an easy part and a hard part. Both parts do similar work but one part does much more work than the other:
void work(int n) {
volatile int i=0; //don't optimize away
while(i++ < n);
}
void easy() { work(1000); }
void hard() { work(1000*1000*1000); }
int main() { easy(); hard(); }
Here, work() is a do-nothing loop. easy() executes a thousand iterations of that loop and hard() executes a billion iterations. We therefore expect main() to spend most of its time in hard() and only a tiny fraction in easy().
Now let's profile the program with gprof:
gcc -o try try.c -pg ./try # saves stats to gmon.out gprof try gmon.out
On my machine, this prints the following info:
self self total seconds calls s/call s/call name 3.84 2 1.92 1.92 work 0.00 1 0.00 1.92 easy 0.00 1 0.00 1.92 hard
gprof's lie is marked in red; it says easy() and hard() took the same amount of time, instead of hard() taking a million times more to run.
What happened? Can we trust anything that gprof says? Which parts of its output are entirely wrong like this "easy() is the same as hard()" business and which parts are roughly correct, give or take a measurement error? To answer this, we need to briefly discuss how gprof works.
Roughly, gprof's two sources of information are profil() and mcount():
- profil() – a cousin of creat() in that it could have been spelled with an "e" as well – updates an instruction address histogram every 10 milliseconds. That is, 100 times a second the OS looks which instruction the program is executing, and increments a counter corresponding to that instruction. So the share of increments corresponding to a function's body is proportionate to the share of time the program spent in the function.
- mcount() is a function called by assembly code generated by
gcc -pg. Specifically, when a function is entered, it calls mcount() to record a call to itself from the caller (the caller is generally easy to identify because it necessarily passes a return address to your function and that address points right into the caller's body.) So if f() calls g() 152 times, mcount(f,g) will be called 152 times.
With this in mind, we can roughly tell what gprof knows. Specifically, it knows that:
- easy() and hard() were both called once; work(), called from each, ran twice. This info is from mcount() and it's 100% reliable.
- The program spent almost no time in the code of easy() and hard(), and most of its time in the code of work(). This info is from profil() and it's rather reliable – because the program ran for >3 seconds, which means we had >300 increments in our instruction histogram. If almost all of these increments are in work(), that's significant enough.
What about the share of time easy() spent in its call to work(), and the share of time hard() spent in work()? By now we know that gprof knows absolutely nothing about this. So it guesses, by taking 3.84 – seconds spent in work(), a reliable number – and divides it between easy() and hard() equally because each called work() once (based on mcount(), a reliable source) – and we get 1.92. This shows how bad results can be produced from perfectly good measurements, if passed to the wrong algorithm.
More generally, gprof's output falls into the following categories, listed in decreasing order of reliability:
- Number of calls: 100% reliable in all parts of the report. (I think; please correct me if I'm wrong.)
- Self seconds in the "Flat profile" (time spent in a given function not including children): reliable to the extent that 100 samples/second is statistically significant given the number of hot spots and the total runtime.
- Seconds attributed to call graph edges (contribution of children to parents, total runtime spent in self+children, etc.): possibly dead wrong. Only trust it if there's zero code reuse in a given case (that is, f() is only called by g()), or if the function in question is known to take about the same time regardless of the call site (for example, rand()).
BTW, the fact that gprof lies doesn't mean that its documentation does; on the contrary, `man gprof` says, in the BUGS section:
The granularity of the sampling is shown, but remains statistical at best. [this refers to the limited reliability of profil's histogram.] We assume that the time for each execution of a function can be expressed by the total time for the function divided by the number of times the function is called. Thus the time propagated along the call graph arcs to the function's parents is directly proportional to the number of times that arc is traversed. [this refers to the absolutely unreliable way in which profil's "self time" data is combined with mcount's call graph data.]
Unfortunately, users tend to read tools' output without reading documentation. (The ability of users who aren't into profiling tools to understand the implications of this passage is a separate question.)
The man page also refers to papers from 1982 and 1983. An age of over three decades is a good reason to cut a program some slack. In a way, gprof's age is not only a source of its limitations, such as only 100 samples per second, but also a source of its strengths, such as fast execution of profiled code and wide availability.
Now let's look at a more modern profiler called callgrind – a valgrind plugin. Being more modern, callgrind has a few advantages over gprof – such as not lying in its call graph (though some would debate that as we'll see), and coming with a GUI program to visualize its output called KCachegrind.
KCachegrind the viewer (as opposed to callgrind the measurements collector) does lie in its call tree as opposed to call graph as we'll shortly observe. But first let's have a look at its truthful reporting of the situation with easy() being easier than hard():
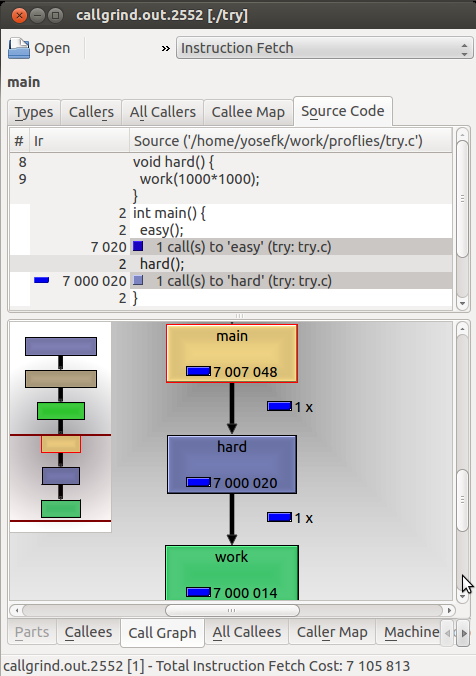
As you can see, easy() isn't even shown at the graph (KCachegrind hides things with insignificant cost); you can, however, see the cost of main's call to easy() and hard() at the source view – indeed easy() is ~1000x faster than hard().
Why 1000x and not 1000000x? Because I changed hard() to run a million iterations instead of a billion, bringing the difference down to 1000x. Why did I do that? Because callgrind is slow – it's based on Valgrind which is essentially a processor simulator. This means that you don't measure time - you measure things like instructions fetched and cache misses (which are interesting in their own right), and you get an estimation of the time the program should take given these numbers and your processor model.
It also means callgrind is slow. Is it slower than gprof? Not necessarily. With gprof, code runs at near-native speed, but you only get 100 data points per second. With callgrind you get much more data points per second. So for a hairy program, with callgrind you get statistically significant data more quickly – so effectively callgrind is faster.
But for a simple program with just a couple of hot spots, callgrind is slower because if the program has a costly part 1 and then a costly part 2, it'll take callgrind more time to even get to part 2, whereas gprof, with its near-native speed, will give you good enough data from its fast run.
So much about speed; now let's look at a case where KCachegrind lies to us, and then we'll discuss why it happens.
To expose the lie, we'll need a more complicated program. We'll achieve the required complexity by having two worker functions instead of one, and then adding a manager – a function that does nothing except calling the two workers with the number of iterations to run.
How does the manager decide the number of iterations each worker should run? Based on the project requirements, of course. Our "projects" will be two more functions, each calling the manager with its own pair of iteration numbers for the two workers.
void worker1(int n) {
volatile int i=0;
while(i++<n);
}
void worker2(int n) {
volatile int i=0;
while(i++<n);
}
void manager(int n1, int n2) {
worker1(n1);
worker2(n2);
}
void project1() {
manager(1000, 1000000);
}
void project2() {
manager(1000000, 1000);
}
int main() {
project1();
project2();
}
As you can see, both workers work on both projects, but each project is mostly done by one of the workers, the other contributing 1000x less work. Now let's see what KCachegrind says about this; we need to run callgrind, which can be done without special compilation flags:
gcc -o try2 try2.c valgrind --tool=callgrind ./try2 kcachegrind `ls -tr callgrind.out.* | tail -1`
Here's what we'll see:
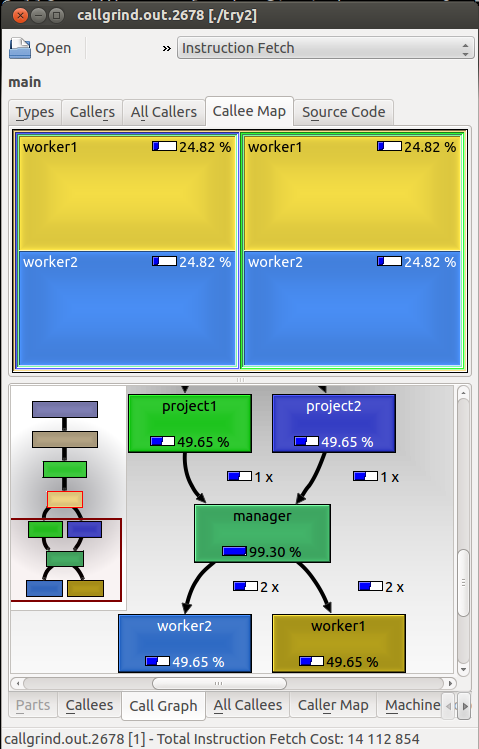
The bottom part of the screen shows us truths, but the top part shows falsehoods.
The truth is that each project called the manager once; the manager called each worker twice; and each worker did half the work in the program – all shown at the call graph at the bottom. However, at the top, each of the project functions occupies half the window and shows that worker1 and worker2 each did half of the work in each project - which couldn't be further from the truth.
This falsehood is reported by the call tree (or "callee map" as KCachegrind calls it) – a view which is supposed to show, for each function, the share of work done in each of its callees relative to the work done by all those callees together (as opposed to the call graph which only links to the called functions and tells how many times they were called by that caller – and their share of work in the entire program.)
Why does the call tree tell a falsehood? Again, because it doesn't know the truth. KCachegrind visualizes callgrind's measurements, which include the number of times f() called g() and the time spent in calls from f() to g().
This is more that gprof's information – way more. gprof only knows how much time was spent in f() and g(), and how many times f() called g(). Callgrind also measures how much time was spent in g() specifically when it was called from f(). In particular, this means that KCachegrind's source view gives a perfectly reliable measurement of the time spent in f plus all its callees – something which users take for granted and something which gprof only guesses, often wildly wrongly.
However, this information is not enough to know what the call tree needs knowing to show the truth. Specifically, you only know that manager() spent the same time in calls to worker1() and worker2() overall; you have no idea how much time it spent in each worker when called from project1() and project2(). So you can't reliably plot the share of time worker1() and worker2() spent inside project1() or project2(); you can only guess, often wildly wrongly.
(In fact, you can't tell if manager() even called worker1() when called from project1(); perhaps it didn't – all you know is that manager called worker1() in some context. Some people conclude that the call graph is "incorrect"; in fact it is correct, the question is if you understand what you see the way you're supposed to – you aren't supposed to think that every path through the graph actually happened, only every edge. Another question is how upset you are when you find out (someone with a lot of "manager" functions doing nothing but dispatching might be very upset.) This example certainly broadens the gray area between "truth" and "lies" in profilers' output.)
Callgrind has something which appears like a possible workaround: --separate-callers=N. What this does is it measures things per call stack of size N instead of
per call "arc". That is, instead of having a measurement for the arc from manager() to worker1() and a measurement for
manager()->worker2(), it measures separately for project1()->manager()->worker1(),
project1()->manager()->worker2(), project2()->manager()->worker1(), etc.
Unfortunately, KCachegrind didn't manage to open the resulting output file on my machine, nor did it help when I replaced the ticks (') separating the function names (which get concatenated together) with underscores (_). However, the textual data produced by callgrind indeed shows the truth:
fn=(726) worker2'manager'project1 5 3 +1 1 +1 7000008 +1 2 fn=(736) worker2'manager'project2 5 3 +1 1 +1 7008 +1 2
This shows that worker2() did 1000x more work when called (through manager()) from project1() than it did when called from project2() – as we know it did.
Having looked into the details of two particular examples, we'll proceed to a more general discussion of profilers and profile visualization tools.
Using no profiler at all is better than hoping it'll save the day
I know a few people who like to optimize code and think optimization is important, and who mostly ignore profilers. I know a few other people who claim that a good profiler is the necessary and sufficient prerequisite for optimization. More often than not, such people are not particularly fond of optimization, and their code will be slower than the code of above-mentioned profiler-bashers, before as well as after optimization.
The examples above supposedly show a part of the reason why "a good profiler" is not at all trivial to use.
Basically among the many opinions, there are two extreme ones sounding along the lines of:
- You don't know where your bottlenecks are going to be, therefore don't bother to optimize before measuring.
- You don't know where your bottlenecks are going to be – nor will you be able to measure them because adequate measurement and analysis tools plus test scenarios covering the relevant possibilities are hard to come by. Therefore, conserve resources if there's even a slight chance that the code will be a bottleneck.
In my experience, the first viewpoint results in slower code and is less consistent internally. That is, for someone who's not into optimization, a profiler is just not the force multiplier that he thinks it is. That's because he won't put the mental effort required to make an effective use of the profiler for the same reasons making him write slow code in the first place: he just doesn't like all this performance stuff.
The trouble with this being that profilers are not things magically telling you what to do without concentration on your behalf.
You need to understand how a profiler works to use it well
When I first realized how gprof lies in its call graph, I was so offended that I stopped using it for a long while. The problem with profilers is that not all the data is gross lies, but some is, and without knowing which data is likely to be wrong, you might trust things that you shouldn't, scratch your head to the point of hair loss, and then abandon the tool altogether once you realize how it routinely betrays your trust.
With KCachegrind, I came up with the example where it lies based on my knowledge of the callgrind output format – something I know because we (specifically, GK) added support for that format to our in-house profiling tools at work. I wouldn't guess that the Callee Map view is unreliable otherwise. Like most users, I rarely read the docs unless something clearly refuses to work altogether. The stats in the call graph as well as the source view are perfectly reliable. How would I know some other stats aren't?
The extent to which you warn the user about possible implications of assumptions in your software is a tough question for all programmers. Should KCachegrind have a big red warning "I might be misleading you" at its "map" views? A "true power user" doesn't need the warning because they know how the tool works anyway. A "truly careless user" wouldn't read the explanation linked to from the red warning and would just be scared away. Only a "middling user" irresponsible enough to not read the docs but responsible enough to read text linked to from big red warnings might benefit from such design. But how many such users are there compared to the rest?
My own experience here is depressing – nobody, not even the smartest folks, is willing to read anything unless they came here to read. As in, when you're a tutorial that people intend to read, you can tell things to people and they listen. When you're an error message, people read you to the extent necessary to make you go away. And when you're a warning, people ignore you. It sucks to be a warning.
So I'm pessimistic about big read warnings. As to tutorials – people don't expect profilers to be complicated enough to warrant a tutorial, so they probably won't allocate time specifically to read one. They're wrong, but they won't.
Choosing a profiler is hard
There's no perfect profiler – it's a tradeoff, or rather a bunch of tradeoffs. Let's see how complicated those tradeoffs are by comparing gprof, callgrind and Google's CPU profiler:
- gprof is fast, requires a special compilation, gives you "self time" based on 100 instruction address samples per second, precise call counts, and often bogus "children time" information.
- callgrind is slow, requires no special compilation, gives time estimations based on event counting, several order of magnitudes more data points per second (making it "effectively faster" for some use cases but not others), precise call counts as well as precise "events counted during a call to each child" information, and comes with a viewer giving correct though possibly misleading call graph and often bogus "map" views.
- Google's CPU profiler is fast, requires no special compilation unless you're on a 64b platform without a working unwind library, uses a configurable amount of samples per second (default: the measly 100, I wonder why), lacks precise call count information, logs full call stacks unlike gprof and callgrind without –separate-callers, but then converts data to many viewing formats where the extra info is lost (such as the callgrind format). You do get more informative view of the profiling data in some cases.
So basically each of these profilers is better than the rest in some way and worse in some other way (for instance, gprof, at first glance the awful, ancient profiler, is actually your shortest path to precise call counts, which may well be the thing you need the most). And that's before discussing things like the ease of getting a working version for your platform.
As it often is with complicated things, the choice is made harder by the fact that you don't realize many of the implications until after you gained some experience with the tool. I don't think I know what questions to ask about a new profiler, even though I'm relatively savvy. I do realize that I want to understand how it works in a lot of detail.
Not all errors are "noise"
If you're listening to an analogue recording and there's a "shhhh" sound, it's "noise". If, however, someone is yelling near you, then this louder noise isn't "noise" in the mathematical sense – it's another signal. And if someone has overwritten your original recording, then there's only another signal left and none of yours. There's also noise on top of that other signal, but that noise is the least of your troubles.
Not everything standing between you and your signal is "noise"; sometimes it's an error making you look at the wrong signal.
With profilers, people intuitively expect "measurement noise" – a profiler measures time (or some other cost) and no measurement device is perfect. People are willing to accept that – but they do expect fidelity in the assignment of costs to context. "Context" is source lines, functions, and call sequences; people (correctly) think of context as something logical where the concept of "measurement errors" doesn't apply; it's either correct or not.
Unfortunately, people are right, but the conclusion is the opposite of the natural expectation: "context" is indeed a logical concept and not a continuous quantity – and therefore, when the tools give you wrong information, it's really wrong, as in completely detached from reality, and not something "roughly right" give or take a measurement error.
(Our examples focusing on call sequences are rather benign, in a way; for real fun, we could discuss the fidelity of assigning costs to source code lines in optimized programs. Even with a nice assembly listing linking to the various source files from which code was inlined, like the listing provided by KCachegrind, it's... let's say less than easy.)
The upshot is that many errors in profilers' output are not something that can be fixed by running the program more times to get more statistically significant results. Rather, you have to know where the results are only distorted by noise and where there can also be logical errors rendering the numbers meaningless.
Presentation errors can exist without measurement errors
...As evidenced by KCachegrind's false presentation of callgrind's or Google profiler's correct results, or by gprof's false conclusions based on reasonable numbers reported by profil() and perfect numbers from mcount().
To add to the previous point, measurement errors are more likely to be "noise" than presentation errors, which are more likely to tell something unrelated to the truth.
Conclusion
Profiling is trickier than we tend to assume, and as someone developing profilers, I understand programmers who're good at optimization and who mostly ignore profilers. A profiler could help users get way more mileage if it found a way to convince them to actually read a thorough, memorable explanation of its strengths and weaknesses.