concurrent (noun): Archaic. a rival or competitor.
Two lines that do not intersect are called parallel lines.
In this piece, I disagree with Joe Armstrong and Rob Pike, basing my argument on the differences between vending machines and gift boxes (illustrated with drawings carefully prepared in Microsoft Paint).
Parallelism and concurrency are both very fashionable notions. Lots of languages and tools are advertised as good at these things – often at both things.
I believe that concurrency and parallelism call for very different tools, and each tool can be really good at either one or the other. To oversimplify:
- Erlang, Rust, Go and STM Haskell are good at concurrency
- Flow, Cilk, checkedthreads and parallel Haskell are good at parallelism
It's possible for both kinds of tools to co-exist in a single language or system. For example, Haskell appears to have good tools for both concurrency and parallelism. But it's still two different sets of tools, and the Haskell wiki explains that you shouldn't use the concurrency tools if you're after parallelism:
Rule of thumb: use Pure Parallelism if you can, Concurrency otherwise.
The people behind Haskell realize that one tool for both isn't good enough. It's a similar story with the new language ParaSail – it offers both kinds of tools, and advises to avoid its concurrency features in parallel, non-concurrent programs.
This is in stark contrast to the opinion of some people primarily interested in concurrency, who think that their tools are a great fit for parallelism. Rob Pike says Go makes parallelism easy because it's a concurrent language:
Concurrency makes parallelism (and scaling and everything else) easy.
Likewise, Joe Armstrong claims that Erlang is great for parallelism because it's a concurrent language. He goes as far as to say that seeking to parallelize "legacy" code written in non-concurrent languages is "solving the wrong problem".
What causes this difference in opinions? Why do Haskell and ParaSail people think you need separate tools for concurrency and parallelism, while Go and Erlang people think that concurrent languages handle parallelism just fine?
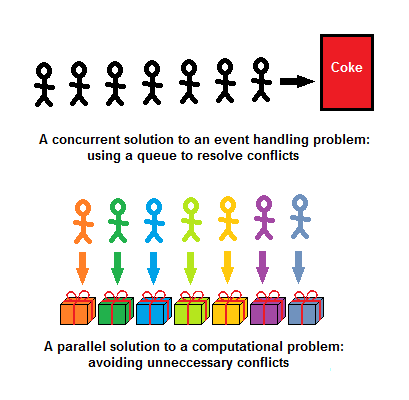
I think people reach these different conclusions because they work on different problems, and develop a different perception of the basic distinction between concurrency and parallelism. Joe Armstrong has drawn a picture to explain how he sees that distinction. I'll draw you a different picture – but first, here's a reproduction of his:
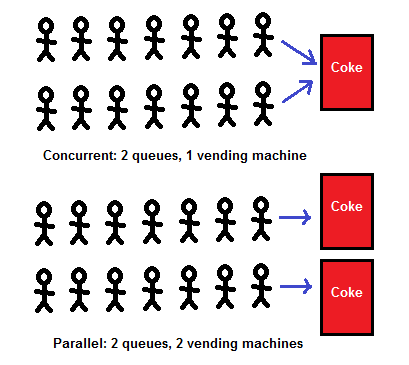
Actually many aspects of concurrency are present with just one queue, but I reproduced the 2 queues from Armstrong's original drawing. So what does this picture say?
- "Parallel" means that you serve Coke faster.
- "Parallel" doesn't mean much else – either way, it's the same concurrent problem.
- Who gets Coke first depends on who gets in line first.
- In a way it doesn't matter who gets Coke first – they all get a can of Coke one way or another.
- ...except perhaps for the few last ones, if the machine runs out of Coke – but that's life, man. Somebody has to be the last.
Indeed, that's all there is to it with a vending machine. What about giving gifts to a bunch of kids? Is there a difference between coke cans and presents?
In fact there is. The vending machine is an event handling system: people come at unpredictable moments, and find an unpredictable amount of cans in the machine. The gift boxes is a computational system: you know the kids, you know what you bought, and you decide who gets what and how.
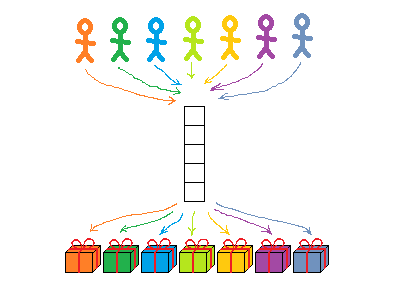
In the gift boxes scenario, "concurrent vs parallel" looks very different:
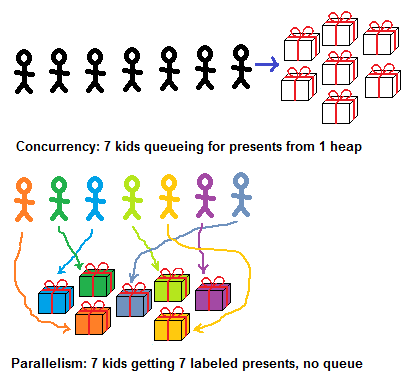
How is "concurrent" different from "parallel" in this example?
- Concurrent present-dealing is a lot like a vending machine: who gets what depends on who got there first.
- Parallel present-dealing is not like that: each present is labeled, so you know who gets what.
- In the concurrent case, a queue is necessary – that's how you avoid two kids fighting over a present/two tasks corrupting a shared data structure.
- In the parallel case, a queue is not necessary. No matter who gets where first, they all end up with the right present.
Queueing in front of a gift heap is concurrent in that archaic sense of "rivalry, competition": you want to be there first, so that it's you who gets the Lego set. In Russian, "concurrent" (pronounced kon-koo-rent) is the contemporary word for "competitor".
With labeled gifts, there's no competition. Logically, labels "connect" each kid with his gift, and these are parallel, non-intersecting, non-conflicting lines. (Why did I draw the arrows so that they do intersect? We'll get back to it later; a good way to think of it is, kids'/processors' paths do cross as they search for their gifts/data – but those intersections are not conflicts over who gets what.)
Computation vs event handling
With event handling systems such as vending machines, telephony, web servers and banks, concurrency is inherent to the problem – you must resolve inevitable conflicts between unpredictable requests. Parallelism is a part of the solution - it speeds things up, but the root of the problem is concurrency.
With computational systems such as gift boxes, graphics, computer vision and scientific computing, concurrency is not a part of the problem – you compute an output from inputs known in advance, without any external events. Parallelism is where the problems start – it speeds things up, but it can introduce bugs.
Let's proceed to discuss the differences between computational systems and event handling systems. We'll start with obvious things, like determinism, but there are many more subtle consequences.
Determinism: desirable vs impossible
In computational systems, determinism is desirable because it makes life easier in many ways. For example, it's nice to test optimizations and refactorings by observing that results didn't change – which you can only do with deterministic programs.
Determinism is often not strictly required – you may genuinely not care which 100 images you find as long as they all have kittens in them, or exactly what approximation of PI you compute as long as it's somewhere between 3 and 4. Determinism is merely very nice – and possible.
In event handling systems, however, determinism is impossible, in the sense that it is a requirement for different orders of events to produce different results. If I got there first, I should get the last Coke can, the last dollar in the shared bank account, etc. If you beat me to it by a millisecond, then it should go to you.
Of course, for basic debugging, you can always run the system completely serially, handling one event a time. But once you make it a bit more realistic and start handling events without first finishing everything that you were doing, you can no longer expect a specific result.
Even in a debugging environment, if you replay an event log with two users racing to withdraw money from a shared bank account, you'll run the thing twice and it might reach two different final states. The number of possible final states is exponential in the number of conflicts.
Ouch.
Sign of parallel safety: determinism vs correctness
How do you know that you have no bugs due to the different ordering of events?
In computational systems, if you get the same result every time, you probably have no parallelism bugs – even if the result is busted. Dog pictures instead of cats means you have bugs – but not parallelism bugs if it's the same dogs every time.
In event handling systems, the only sure sign of not having parallelism bugs is if you always get correct results.
With two users racing to withdraw money, you can't expect to always reach the same result. What can you expect, assuming the bank isn't buggy? Many things. You (presumably) can never have a negative account balance, you (presumably) can't drain a bank account twice, in effect creating money, etc.
If none of these wrong things ever happen, then you got yourself a functioning bank, otherwise you have a bug. With a telephony system, it's similar – except that there's a different set of requirements defining "correct results".
There's no general way to tell if there are timing-related bugs without understanding the aspects of the system having nothing to do with timing.
Ouch!
Parallelism bugs: easy to pinpoint vs impossible to define
With labeled gift boxes, parallelism bugs are trivial to spot – even if the labels are in Chinese, and you can't read Chinese:
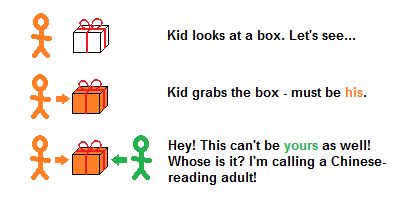
Even if you can't read the labels, knowing that they exist is enough. If two kids fight over a box, then something is wrong and you call an adult who can read the labels.
If you're an automated debugging tool, and you don't know which task is supposed to process which data, it's enough to know that a task shouldn't access data modified by another task. If that happens, you tell the programmer, so that he properly assigns data to tasks without conflicts.
Such tools aren't hypothetical – they're out there. Cilk comes with a tool that does that. Checkedthreads has a Valgrind-based tool that does that.
Parallel Haskell doesn't have to do it – because you have no side effects to begin with, guaranteeing zero conflicts when things are evaluated in parallel. But even with dynamic checking instead of static guarantees, your parallelism bugs are basically just gone.
The upshot is that in computational systems, you don't need to know much to flag bugs and to point to the exact problem they cause. "Here's the box they were fighting over".
In event handling systems, a responsible adult must be much more knowledgeable to maintain discipline.
To be sure, there still is a weaker, but universal rule which always applies: you can't touch anything if someone is already busy with it. You must wait your turn in a queue. An adult can make sure this rule is followed, which is better than nothing. But it's not enough to prevent many common kinds of mischief:
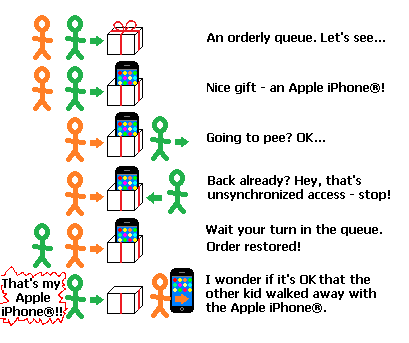
Someone approaching the presents without queuing is clearly wrong – bug detected, order restored.
But someone unpacking a present, leaving the queue, and coming back to find that the present was taken by someone else could be wrong – or it could be OK. After all, that other kid waited his turn, so the only universal rule of event handling systems was followed – but not necessarily the specific rules of how we give out presents around here.
Here's how these problems look in code. The following buggy money transfer implementation can be flagged as buggy by an automated debugging tool:
src.balance -= amount dst.balance += amount
Here we have no synchronization at all – src.balance can be modified by two processes without one of them waiting for the other to be done with it. So you could lose some of the decrements or what-not. A data race detector like Helgrind will spot this bug by monitoring memory accesses and observing the lack of synchronization – just as easily as Cilk's or checkedthreads' checker.
However, the version below is probably still buggy, but it would look fine to data race detectors:
atomic { src.balance -= amount }
atomic { dst.balance += amount }
Here, "atomic" means that everyone has to wait before modifying the balances in some sort of queue – possibly a very fancy sort of queue, but a queue nonetheless; more on that later. Orderly queuing makes data race detectors happy – but is there still a bug?
A thread could be suspended after decrementing src.balance but before incrementing dst.balance, exposing an intermediate state where money is "temporarily lost". Is this a problem? Perhaps. Do you understand banking? I don't, not really – and Helgrind surely doesn't.
Here's a more obviously wrong program:
if src.balance - amount > 0:
atomic { src.balance -= amount }
atomic { dst.balance += amount }
Here, a thread could test that src.balance has enough money to withdraw a given amount, and go to pee. Another thread arrives, makes a similar test and gets busy withdrawing the money. The first thread comes back, is put into some queue, waits his turn and withdraws its own amount – which could have become illegitimate, the first thread having withdrawn too much already.
This is a lot like coming back and realizing that another kid has walked away with your Apple iPhone®. It's a race condition which isn't a data race – that is, it happens despite everyone's civil and polite queuing.
What's a race condition? It depends on the application. I'm sure the last snippet is buggy, but I'm less
sure about the previous snippet, and it all depends on how the bank works. And if we can't even define "race conditions" without
knowing what the program is trying to do, we can't hope to automatically detect them.
Of course you can also not have race conditions. All you have to do is implement the entire withdrawal atomically, and of course all approaches to concurrency let you do it.
The trouble with race conditions though, as opposed to, say, null pointer exceptions, is that you can feed the program bug-triggering inputs again and again, and the thing will only reproduce once in a blue moon. Here's where deterministic, automated debugging could be really handy, flagging the bug every time you feed those inputs. Unfortunately, it's impossible with event handling systems.
"Ouch" again.
Queues: implementation detail vs part of the interface
With labeled gifts, you don't need a queue. Everyone can just go and take their present.
Or maybe not, not really. Thousands of kids getting thousands of labeled presents will need a queue or several, or else they'd be running into each other. How those queues work doesn't matter in the sense that everyone ends up with the same present anyway. The choice of a queuing method does affect how much time you wait for your present though.
That's why I drew the "logically parallel" lines connecting everyone to their labeled gifts so that they intersect – even though these aren't "actual conflicts" over who gets what. (I'm very careful with my metaphors and my Microsoft Paint art – very careful.)
4 processors accessing unrelated data items through a single memory bus is when "logically parallel lines technically cross", and in effect processors will have to wait in some hardware-level queue to make it work. 1000 logically independent tasks distributed to these 4 processors through a load balancing scheduler will again need queues to work.
There are almost always many queues even in a fully parallel, conflict-free system – but they're an implementation detail and they shouldn't affect results. You get the same thing no matter what your place was in any of the queues:
Conversely, in a concurrent system, the queue is right there in the interface:
- A semaphore has a queue of threads waiting to lock it, and who gets there first will affect results.
- An Erlang process has a queue of messages, and who sends a message first will affect results.
- A goroutine listens to a channel, and the order of writes to a channel affects results.
- With transactional memory, everyone failing to commit a transaction is queuing.
- With lock-free containers, everyone failing to update the container is queuing.
With event systems, you can have simple queues or fancy queues, but they are all explicit queues in the sense that order often affects results, and that's OK – or it could be a race condition, go figure.
With computational, parallel, conflict-free systems, order shouldn't affect results – and you want tools to make sure the system is indeed conflict-free.
Rob Pike shows in his slides how easy it is to build a load balancer in Go. Sure it's easy. Go is for concurrency and concurrency is all about queues, and so is load balancing. Not that load balancers are very hard in any language, but yeah it's particularly easy in concurrent languages.
But that's one part of the parallelism story; the next thing you want is either static guarantees of not having conflicts, or dynamic checking. I'm not saying it can't be done in Go – sure it can be done – just that without having it, you underserve computational systems. And once you do have it, it's a different set of interfaces and tools from channels and goroutines – even if underneath it's implemented with channels and goroutines.
Importance of preemption
So conflict prevention/detection is something computational systems need that concurrency tools don't provide. Are there things that concurrency tools do provide that computational systems don't need?
Sure – explicit queues, for starters. Not only aren't they needed, but explicit queues get in the way of computational systems, because as we've seen, queues lead to race conditions that aren't data races and you can't pinpoint those.
Another thing computational systems don't really need is very cheap preemptable threads/processes.
With event handling systems, you sometimes want to react to many different events very quickly, which takes many preemptable processes. You want to have 10000 processes stuck in the middle of something, and process number 10001 can still get activated immediately when an event arrives. This can't work unless preemptable processes are very cheap.
With computational systems, it's nice to have cheap tasks that you can map to the relatively expensive OS threads – but tasks are not as powerful as processes. You don't activate tasks upon events. What tasks do is they wait in various queues, and get processed when a worker thread becomes idle to run them. Unlike the case with goroutines or the like, you can't have more tasks in flight than you have OS threads – and you don't need to.
Tasks can be done nicely with fairly traditional runtimes – as opposed to full-blown cheap processes/goroutines/whatever, which seem to me to need more work at the low-level runtime system side of things.
This shows how platforms aiming at concurrency not only under-serve computational systems, but over-serve them as well.
(To be fair, it is theoretically conceivable to gain something from preemption in a computational system – namely, it could improve throughput if it lets freshly created tasks which are a part of the critical path preempt in-flight tasks which are not. However, in my long and sad experience, a scheduler actually knowing what the critical paths are is little more than a theoretical possibility. And a dumb greedy scheduler has no use for preemption.)
Differences among tools from the same family
Tools aimed at concurrent event systems are not all alike, nor are tools aimed at parallel computational systems. They're from the same family, but there are substantial differences.
- Erlang will not let processes share memory at all. This means you never have data races, which doesn't particularly impress me because as we've seen, data races are easy to find automatically – and race conditions are not at all eliminated by not sharing memory. The nice thing though is you can seamlessly scale to multiple boxes, not just multiple cores in the same chip.
- Rust won't let you share memory unless it's immutable. No easy multi-box scaling, but better performance on a single box, and no need for data race detectors, which can have false negatives because of poor test coverage. (Actually it's not quite like that – here's a correction, also explaining that there are plans to add parallelism tools to Rust in addition to its existing concurrency facilities.)
- Go will let you share everything, which gives the most performance at the price of what I think is a tolerable verification burden. For data races, Go has a data race detector, and race conditions will just happen in event systems anyway.
- STM Haskell will let you share immutable data freely, and mutable data if you explicitly ask for it. It also provides a transactional memory interface, which I think is a cool thing to have and sometimes quite a pain to emulate with other methods. Haskell has other concurrency tools as well – there are channels, and if you want to have Erlang's scalability to multiple machines, apparently Cloud Haskell does the trick.
Of course the other big difference is that you'd be programming in Erlang, Rust, Go and Haskell, respectively. And now to computational systems:
- Parallel Haskell will only parallelize pure code. A static guarantee of no parallelism bugs at the cost of having no side effects.
- ParaSail allows side effects, but disallows many other things, such as pointers, and as a result it will only evaluate things in parallel if they don't share mutable data (for example, you can process two array slices in parallel if the compiler is convinced that they don't overlap). Similarly to Haskell, ParaSail has some concurrency support – namely "concurrent objects" which indeed can be shared and mutable – and documentation stresses the benefits of not using concurrency tools when all you need is parallelism.
- Flow appears to be based on a pure functional core, which is restricted even further to let the compiler fully comprehend the data flow in the program, and allowing it to target platforms as diverse as Hadoop and CUDA. Things syntactically looking like side effects, parallel reduction, etc. are supposed to be a layer of sugar atop this core. At least that's my impression from reading the Manifesto, which admittedly I didn't fully understand ("if a morphism is surjective and injective, then it is a bijection and therefore it is invertible" is more obvious to some of us than others.)
- Cilk is C with keywords for parallel loops and function calls. It will let you share mutable data and shoot yourself in the foot, but it comes with tools that deterministically find those bugs, if they could ever happen on your test inputs. What makes uninhibited shared mutable data very useful is when you don't shoot yourself in the feet – when a parallel loop computes stuff with whatever task-local side-effect-based optimizations, and then the loop ends and now everyone can use the stuff.
- checkedthreads is a lot like Cilk; it doesn't rely on language extensions, and all of it is free and open – not just the interface and the runtime but the bug-finding tools as well.
I wrote checkedthreads, so this is the advertisement part; checkedthreads is portable, free, safe and available today in the very mainstream languages C and C++, unlike many systems requiring new languages or language extensions.
With Cilk, there's an effort to standardize it in C++1y or some such, but Cilk wants to add keywords and the C++ people don't like adding keywords. Cilk is available in branches of gcc and LLVM, but it won't run on all platforms at the moment (it extends the ABI) and it hasn't been merged into the mainline for a while. Some newer Cilk features are patented. Not all of it is freely available, etc. etc.
Cilk's big advantage, however, is that it's backed up by Intel, whereas checkedthreads is backed up by yours truly. And if Cilk suits you and you decide to use it as a result of my checkedthreads-related blogging, I will have achieved my goal of automated debugging of parallel programs getting some much-deserved attention.
The upshot is that not all concurrency tools are alike, and different parallelism tools are likewise different – I don't even claim to have pointed out the most important differences between my examples; it's hairy stuff. Still, they're two different families, and the first thing to do is to pick the right family.
Conclusion
We've discussed differences between parallel, computational systems and concurrent, event handling systems. Areas of differences include:
- Determinism: desirable vs impossible
- Sign of parallel safety: same results vs correct results
- Parallelism bugs: easy to pinpoint vs impossible to define
- Queues: implementation detail vs part of the interface
- Preemption: nearly useless vs nearly essential
For event handling systems, concurrency is their essence and parallelism is a part of some solutions – typically good ones (two vending machines is better than one). For computational systems, parallelism is their essence and concurrency is a part of some solutions – typically bad ones (a heap of gifts is usually worse than labeled gifts).
I hope to have gained more clarity than confusion by occasionally conflating "parallelism/concurrency" with "computation/event handling". I also hope I didn't paint too dark a picture of event handling systems – perhaps there are automated verification strategies that I'm not aware of. However it came out, I don't claim that my viewpoint and terminology usage is "the" way of looking at this.
There's value in the angle preferred by some people interested in event handling systems – "concurrency is dealing with several things at a time, parallelism is doing several things at a time". From this angle, parallelism is an implementation detail, while concurrency is in the structure of the program.
I believe there's value in my perspective as well – namely, "concurrency is dealing with inevitable timing-related conflicts, parallelism is avoiding unnecessary conflicts" – "vending machines vs labeled gifts". Here's how the two look like – now with parallel arrows disentangled, as they logically are:
The most important takeaway is that computational code, as opposed to event handling code, can be made virtually bug-free rather easily, using either automated debugging tools or static guarantees.
Handling parallelism using its own tools is nothing new. Rob Pike's work on Sawzall, a specialized parallel language where code is always free from parallelism bugs, predates his work on the concurrent language Go.
However, tools for concurrency appear "louder" than tools for parallelism at the moment – and they can handle parallelism, albeit relatively badly. Loud and bad often crowds out the less visible better. It'll be a pity if better support for parallelism won't be developed as a side effect of "loud concurrency" – or if such support atrophies where already available.
I'd go as far as replying to Armstrong's "parallelizing serial code is solving the wrong problem" with "using 'bare' concurrency tools for computational code is applying your solution to the wrong problem". The simple fact is that C parallelized with the help of the right tools is faster and safer than Erlang.
So here's to "using the right tool for the job", and not having anyone walk away with your Apple iPhone®.